Regressão Linear e Gradiente Descendente: Do zero à Bruxaria

Conteúdo
- 01 — Introdução às Regressões Lineares
- 02 — Método dos Mínimos Quadrados (Sum of Squared Errors: SSE)
- 03 — Método dos Mínimos Quadrados Ordinários (Ordinary Least Squares: OLS)
- 04 — Método do Gradiente Descendente
- 05 — Tentando minimizar a Função de Custo
- 06 — A Regra da Cadeia
- 07 — Aplicando a Regra da Cadeia na Função de Custo
- 08 — Taxa de Aprendizagem (Learning Rate)
- 09 — Aplicando o Método do Gradiente Descendente na prática
- 10 — Criando uma Reta de melhor ajuste com com Scikit-Learn
- 11 — Dividindo os dados em Treino e Teste
- 12 — Pegando o Coeficiente de Determinação R^2 com Scikit-Learn
- 13 — Usando o conceito de Regressão Linear & R2 em um conjunto de dados reais + random_state
- 14 — Fazendo previsões
01 — Introdução às Regressões Lineares
Antes de cair de cara nos códigos e tópicos mais avançados vamos definir algumas coisas bem básicas sobre Regressões Lineares.
As Regressões Lineares mais comuns são as Simples e Múltipla.
- No primeiro caso, a Regressão Linear Simples, tem o objetivo é investigar a influência de uma Variável Independente sobre uma Variável Dependente.
- No segundo caso, Regressão Linear Múltipla, analisa a influência de várias Variáveis Independentes em uma Variável Dependente.
Algo parecido com isso:

Regressão Linear Simples
O objetivo da regressão linear simples é prever o valor de uma Variável Dependente com base em uma Variável Independente.
- Quanto maior for a relação linear entre a Variável Independente e a Variável Dependente, mais precisa é a previsão.
- Isso também significa que quanto maior a proporção da variância da Variável Dependente que pode ser explicada pela Variável Independente, mais precisa é a previsão.
NOTE:
Visualmente, a relação entre as variáveis pode ser mostrada em um gráfico de dispersão (Scatter Plot). Quanto maior a relação linear entre as variáveis dependentes e independentes, mais os pontos de dados estão em uma linha reta.
Veja o exemplo abaixo:

Regressão Linear Múltipla
Ao contrário da Regressão Linear Simples, a Regressão Linear Múltipla permite que mais de duas Variáveis Independentes sejam consideradas. O objetivo é estimar uma variável com base em várias outras variáveis.
NOTE:
A variável a ser estimada é chamada de Variável Dependente (critério). As variáveis que são usadas para a previsão são chamadas de Variáveis Independentes (preditores).
Regressão Multivariada vs Regressão Múltipla:
A Regressão Múltipla não deve ser confundida com a Regressão Multivariada:
- No primeiro caso, a influência de várias variáveis independentes em uma variável dependente é examinada.
- No segundo caso, vários modelos de regressão são calculados para permitir conclusões a serem tiradas sobre várias variáveis dependentes.
Conclusão:
- Em uma Regressão Múltipla, uma Variável Dependente é levada em consideração;
- Enquanto em uma Regressão Multivariada, várias Variáveis Dependentes são analisadas.
Ok, para começar com nossos exemplos práticos em Regressões Lineares vamos imaginar o seguinte… Suponha que nós estamos olhando a relação entre notas de alunos e seus salários.
O código vai ser o seguinte:
OUTPUT:
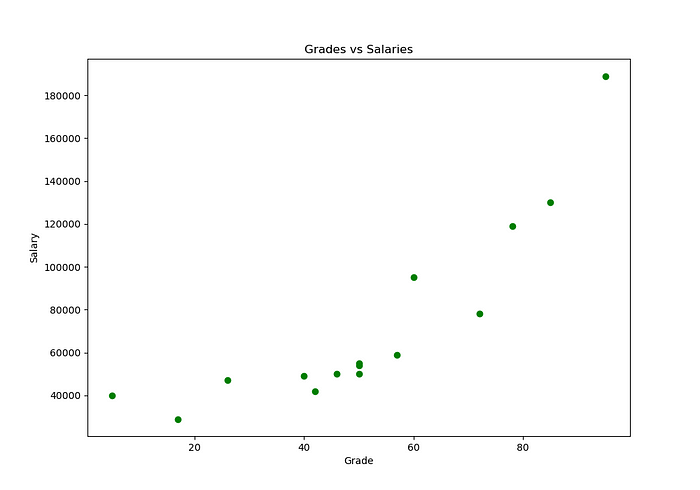
Essas variáveis são conhecidas, respectivamente como:
- Grade (nota): Variáveis independentes, entradas ou preditoras;
- Salary (salário): Variáveis dependentes, saídas ou respostas.
Em uma Regressão Linear é comum denotar as saídas com 𝑦 e as entradas com 𝑥. Se houver duas ou mais Variáveis Independentes, elas podem ser representadas como um vetor 𝐱 = (𝑥₁,…, 𝑥ᵣ), onde 𝑟 (ou n) é o número de entradas.
Mas então, como eu consigo analisar as notas de alunos e seus salários? Bem, existem várias maneiras, porém, vamos ver as mais comuns.
02 — Método dos Mínimos Quadrados (Sum of Squared Errors: SSE)
O método dos Mínimos Quadrados calcula o erro para cada ponto (xi, yi) em relação a média de todas as saídas yi.
Não entendeu? Veja a fórmula abaixo:
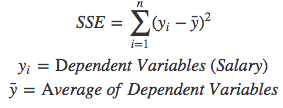
Resumidamente, nós estamos tirando a variância de cada ponto (xi, yi) em relação a média de todos os meus y.
Agora vamos transformar tudo isso em Python para ficar algo mais automatizado:
OUTPUT:
Grade Salary Error Squared Errors
0 50 50000 -22400.0 5.017600e+08
1 50 54000 -18400.0 3.385600e+08
2 46 50000 -22400.0 5.017600e+08
3 95 189000 116600.0 1.359556e+10
4 50 55000 -17400.0 3.027600e+08
5 5 40000 -32400.0 1.049760e+09
6 57 59000 -13400.0 1.795600e+08
7 42 42000 -30400.0 9.241600e+08
8 26 47000 -25400.0 6.451600e+08
9 72 78000 5600.0 3.136000e+07
10 78 119000 46600.0 2.171560e+09
11 60 95000 22600.0 5.107600e+08
12 40 49000 -23400.0 5.475600e+08
13 17 29000 -43400.0 1.883560e+09
14 85 130000 57600.0 3.317760e+09
Sum of Squared Errors (SSE): 26501600000NOTE:
Vale ressaltar aqui que nós estamos elevando todos os erros ao quadrado porque alguns deles vão ser negativos, e como nós queremos somar todos os erros isso acabaria modificando o resultado. Ou seja, estamos deixando todos positivos.
03 — Método dos Mínimos Quadrados Ordinários (Ordinary Least Squares: OLS)
Até então nós estamos utilizando uma abordagem, onde nós tiravamos a variança de cada ponto em relação a média de todos os resultados y.
Agora vamos utilizar uma abordagem que usa uma reta de melhor ajuste para ver se conseguimos um efeito melhor. Ou seja, vamos criar uma reta que fique o mais próximo possível de todos os pontos; Tanto os pontos acima da linha quanto os abaixo.
Para fazer isso, nós podemos utilizar a Equação da Reta para criar uma linha que passe o mais próximo possível de todos os dados:
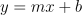
Tenho certeza, todos nós aprendemos essa fórmula na escola. Para Regressão Linear, usamos símbolos como estes para a mesma equação:
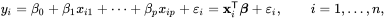
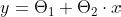

Eu sei que isso pode acabar confundindo um pouco, mas é só se lembrar da Equação da Reta, y = mx + b, onde:
- O meu m (ou a) representa o Coeficiente Angular;
- O meu b representa o deslocamento da Reta.
NOTE:
Para criar essa reta de melhor ajuste nós precisamos dos melhores valores possíveis para os termos m e b para a amostra que estamos trabalhando.
Isso porque os coeficientes m e b variam de valores de acordo com os dados que nós temos.
Ótimo, entendemos a ideia por trás do Algoritmo de Regressão Linear que usa uma reta de melhor ajuste para medir o tamanho dos nossos erros e explicar a relação entre os dados.
Uma maneira de tentar encontrar os valores para os coeficiente m e b é utilizando as seguintes fórmulas:
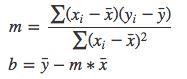

Agora vamos testar essa bruxaria em Python para praticar um pouco:
OUTPUT:
Angular Coefficient (m): 1516
Linear Coefficient (b): -5732.0Ok, agora que nós já temos os melhores valores para os coeficientes m e b para esse conjunto de dados podemos aplicar eles na Equação da Reta e criar a reta de melhor ajuste:
OUTPUT:
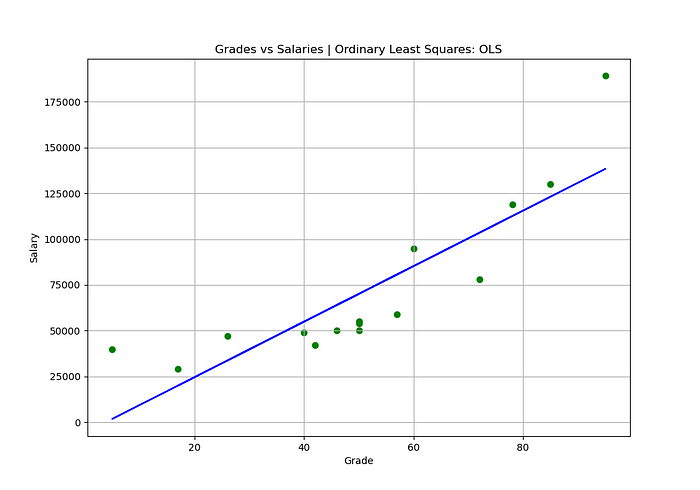

Ótimo, agora é só tirar a variância de cada ponto yi em relação a reta de melhor ajuste:
OUTPUT
NOTE:
Essa saída vai ser um pouco grande por isso vou deixar vocês mesmo rodarem o código para verem como foi.
Mas, resumidamente, a Soma dos Erros foi reduzida significativamente de 26.501.600.000 para 6.958.885.882. Isso porque nós estamos utilizando uma reta de melhor ajuste que tem os melhores valores de m e b para esse conjunto de dados, não apenas subtraindo os pontos (xi, yi) pelo a média de todos os y.
NOTE:
Mas essa solução não é escalonável… Aplicar isso à Regressão Linear foi bastante fácil, pois tínhamos bons coeficientes e equações lineares, mas aplicar isso a algoritmos complexos e não lineares como Support Vector Machine não seria viável. Então vamos encontrar a aproximação numérica desta solução por um método iterativo.
04 — Método do Gradiente Descendente

Calma gente, rss… Eu sei que esse nome “Gradiente Descendente” assusta todo mundo, mas vocês vão ver como é simples. É tudo questão de saber quando e como ele é aplicado.
Então, antes nós estavamos utilizando o Método dos Mínimos Quadrados Ordinários que construía uma reta de melhor ajuste a partir de 2 fórmulas Agora nós vamos ter que criar a mesma reta, porém sem aquelas fórmulas. Isso porque nós vamos utilizar uma abordagem iterativa.
Para começar, vamos imaginar a seguinte história:
Considere que 20 pessoas (incluindo você) são lançadas aleatoriamente no ar em uma cadeia de montanhas. Sua tarefa é encontrar o pico mais alto de todas as montanhas em 30 dias.

Cada um de vocês tem um walkie talkie para se comunicar e um altímetro para medir a altitude. Todos os dias vocês passam horas localizando o pico mais alto possível e relatam sua altitude mais alta do dia a todos os outros.

Suponha que no dia 1 você relate 1000 pés; Outra pessoa informa 1230 pés e assim por diante. Depois, há uma pessoa que reporta 5000 pés, que é o máximo de todos.
Lembre-se de que sua tarefa era atingir coletivamente o pico mais alto de todas as montanhas. O que você faz a seguir no dia 2? No dia seguinte, todos se reunirão em direção à área onde a altitude máxima foi encontrada ontem. Eles pensarão que é provável que o pico mais alto seja nesta área.
Por que alguém que reportou 500 pés ontem procuraria naquela área de novo se há outra área que já tem 5.000 pés?
Portanto, todos os pesquisadores se movem “rapidamente” em direção ao ponto mais alto relatado. Agora, essa ganância pode levar você ao pico mais alto de todas as montanhas, mas também pode levar a um erro enorme…
O cara que estava a 500 pés ontem poderia ter ido em direção a um pico que tinha uma altura de 10.000 pés! E ele o ignorou e foi em direção aquele de 5.000 pé. Você realmente fica preso em um Máximo Local. E não há como saber se você está preso no Máximo Local.
Simulated Annealing:
Existe um Algoritmo que seria útil para nós nesse caso, o algoritmo Simulated Annealing, onde os pesquisadores teriam pesquisado todo o espaço de pesquisa minuciosamente e sem serem tendenciosos para provavelmente encontrar os máximos globais.
Vou deixar alguns exemplos visuais de Simulated Annealing para deixar mais claro:
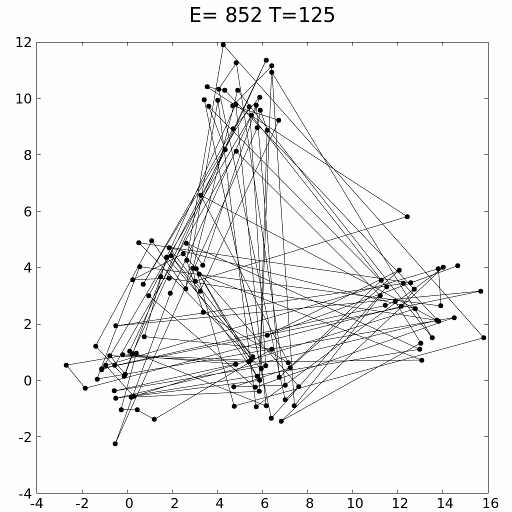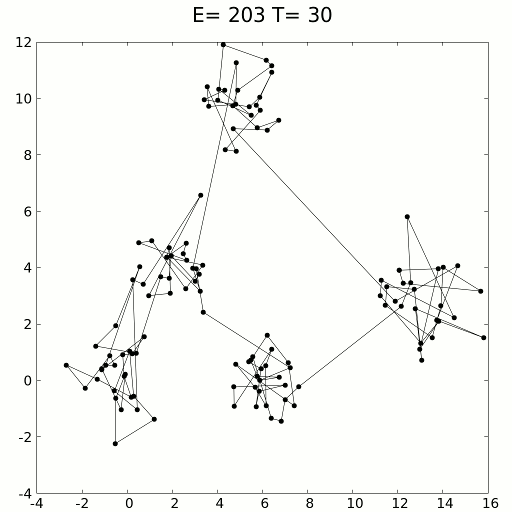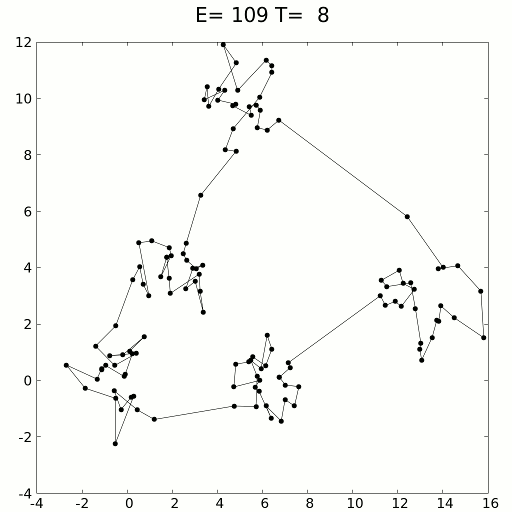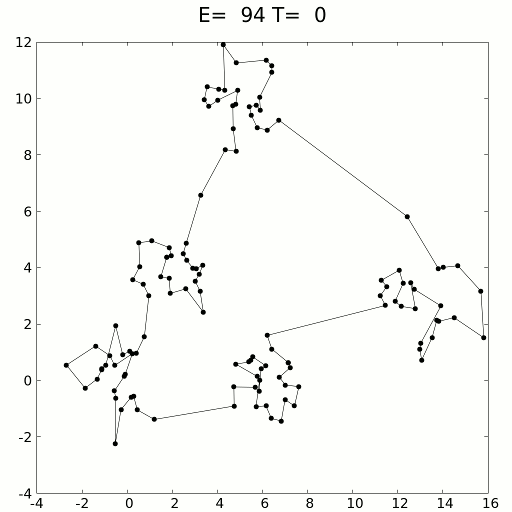
Voltando para o problema das montanhas… Se tivesse como equacionar esse problema das Montanhas, ou seja, transforma isso em Matemática nós só precisaríamos tentar chegar (ou encontrar) o ponto Máximo Global da função, tentando evitar ficar preso em Máximos Locais.
Agora vamos voltar para o nosso problema de Regressão Linear, onde, nós queríamos criar uma reta de melhor ajuste utilizando a Equação da Reta que usa uma abordagem iterativa:
Como assim uma Abordagem Iterativa?
Resumidamente, nós vamos ficar tentando valores para os coeficientes m e b até achar a reta de melhor ajuste para o nosso conjunto de dados.
Um exemplo bem abstrado (e maluco) poderia ser o seguinte:
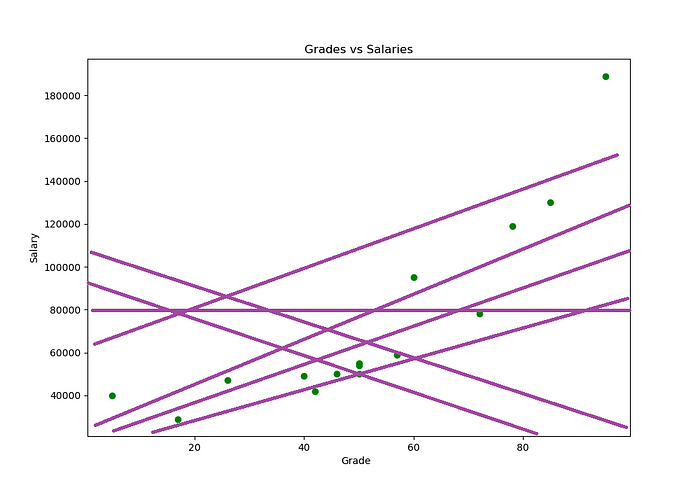
Mas se pensarmos bem, nós resolvemos um problema e agora temos outro (mesmo que mais simples), que é ficar tentando vários valores para os coeficientes m e b até achar a reta de melhor ajuste para o nosso conjunto de dados.

Então, temos um problema hein? Já pensou ter que criar 1 milhão de retas o tamanho do recurso computacional que seria gasto?
Ok temos um problema, como escolher os melhores valores possíveis para os meus m e b? Bem, pensem comigo nas seguintes abordagens:
Primeira abordagem:
Nós podemos ir alterando valores de pouco em pouco, por exemplo, 1 unidade por teste em m e b. O problema é que se tivermos muito longe dos melhores valores para m e b isso vai exigir muito recurso computacional.
Segunda abordagem:
Essa abordagem é muito simples, vamos aumentar valores muito grandes para testes em m e b. Por exemplo, 1000, 500, 300, 100…
Qual a melhor abordagem? AS DUAS!!!
É isso mesmo… Pense comigo, se eu aumentar grandes unidades (valores) para os meus m e b; E a medida que eles vão se aproximando da melhor reta possível eu posso ir diminuindo esses valores até chegar na reta de melhor ajuste para o nosso conjunto de dados.
Ou seja:
Caminhando rápido quando a gente está muito longe; E caminhando devagar quando a gente está muito perto.

Então, o Gradiente Descendente é o bixo de sete cabeças que consegue aplicar esse conceito que nós aprendemos agora. Mas como?
Primeiro, vamos ver aqui a matemática das coisas né:

Agora vamos pegar o nosso gráfico de comparação entre notas de alunos e seus salários:
Suponha que nós selecionamos um desses pontos, o ponto yi, algo parecido com isso:
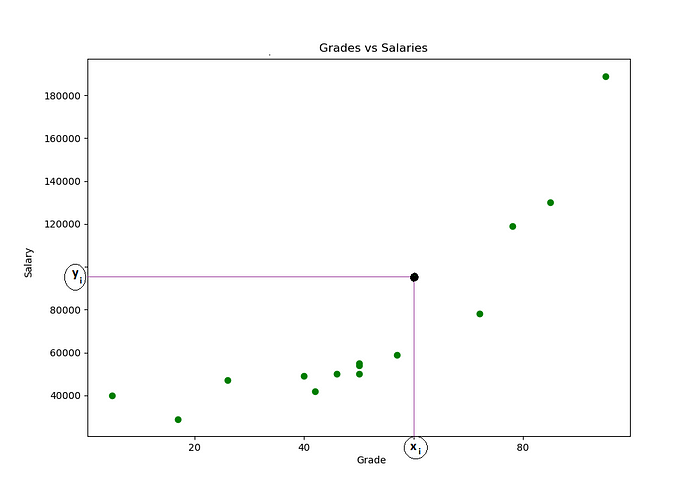
Agora suponha que nós pegamos a equação da reta e desenhamos uma reta qualquer:
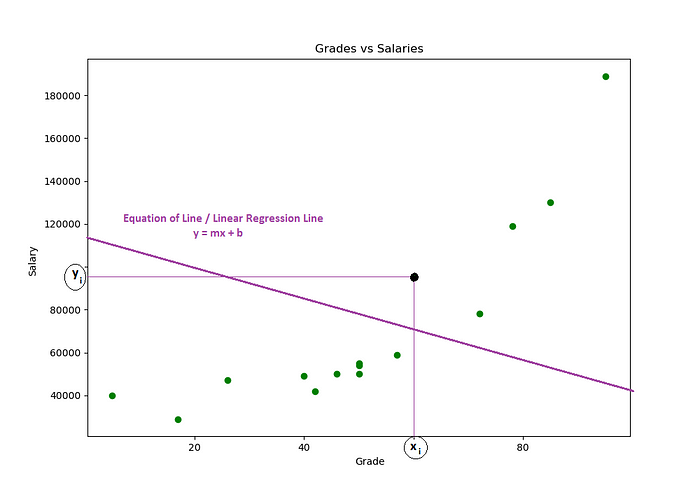
Então, agora nós estamos na seguinte situação:
- Um ponto yi selecionado;
- E criamos uma equação reta com valores aleatórios para os coeficientes m e b.
Agora vem a pergunta chave:
Como eu sei quão distante essa reta está dos meus dados? — Todos eles!
Pode parecer muito difícil, mas é simples:
- 1ª — Eu vou pegar o meu xi
- 2ª — Ver qual foi o resultado da equação da reta nesse ponto.
Não entendeu? Vamos ver isso visualmente:
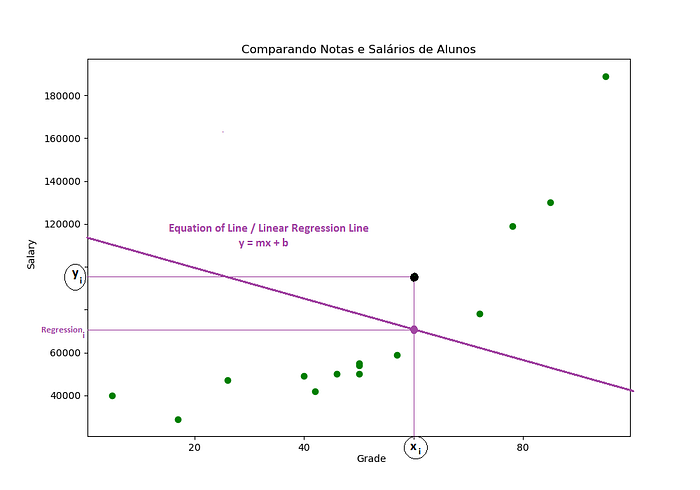
Veja que agora nós temos outro ponto de intersecção, porém esse vai representar minha regressão_i. Mas o que isso tem a ver com a nossa pergunta chave?
Como eu sei quão distante essa reta está dos meus dados? — Todos eles!
Bem, o ideal seria que essa equação da reta passasse bem no nosso ponto yi, mas como podemos ver tem uma distância entre o meu ponto yi e a minha regressão_i.
Ué, mas se temos uma distância entre esses dois pontos é só calcular essa distância não é?

Ou seja, a diferença entre a minha regressão_i e o meu ponto yi:
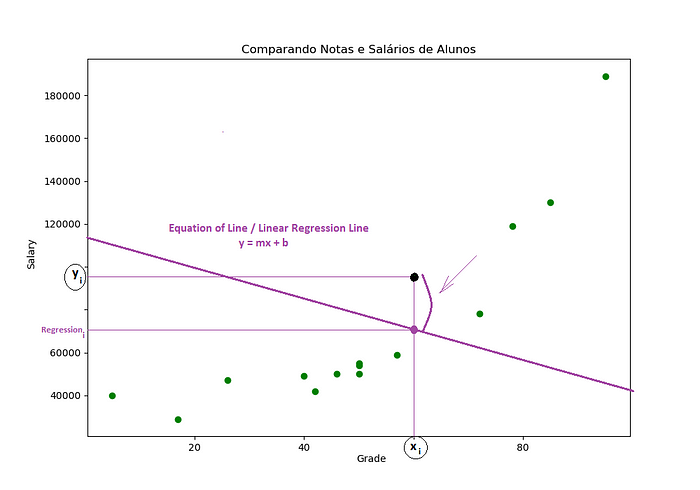
Agora vamos ver alguns detalhes aqui:
- 1ª — Essa distância entre o meu ponto yi e a minha regressão_i é o que nós conhecemos como: Erro para esse ponto yi.
- 2ª — Nós vamos ter que sair medindo esse erro para todos os pontos do nosso gráfico: Ou seja, nós vamos tirar o erro para todas os nossos yi em relação a essa reta que nós criamos.
- 3ª — E por fim, fazer a soma de todos os erros para essa reta:
NOTE:
- Quanto maior esse valor, maior vai ser nosso erro;
- Quanto menor esse valor, menor vai ser nosso erro.
Ok, mas como eu posso equacionar isso?
Bem isso é o que nós conhecemos como Função de Custo, Loss Function, L, J… Existem várias abordagens.
Alguns exemplos são:
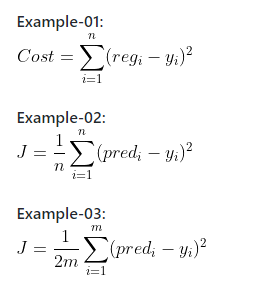
Essas funções vão variar de acordo com o seu problema, Algumas utilizam:
- RMSE;
- MSE;
- MAE
- ErroMédio… etc.
Como nós estamos focando apenas em somar todos os nossos erros e mais nada, vamos ficar com o primeiro exemplo (Example-01) de Função de Custo.
05 — Tentando minimizar a Função de Custo
Ok, nós já temos a nossa Função de custo que vai fazer a soma de todos os nossos erros:
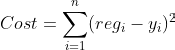
Recapitulando:
- 1ª — Nós traçamos uma reta;
- 2ª — Calculamos o erro para cada ponto na reta;
- 3ª — Por fim, fizemos a soma de todos os erros e conseguimos tamanho do nosso erro.
Até ai tudo bem, calculamos o tamanho do nosso erro para uma reta, mas lembra que nós tinhamos uma abordagem?
Caminhando rápido quando a gente está muito longe; E caminhando devagar quando a gente está muito perto — Para encontrar os melhores valores de m e b.
Ou seja, nós vamos construir outra reta que nós dê um valor menor para a nossa Função de Custo.
Mas como? Simples, nós vamos passar novos valores para os coeficientes m e b:
Então, é ai que entra o conceito de Derivadas, Derivadas Parciais e Mínimos de uma Função.
Suponha que a nossa equação da reta tem o seguinte gráfico (é só um exemplo):
Bem, no exemplo acima nós temos uma parábola (é só um exemplo) com várias Taxas de Variação e nós estamos interessando nos pontos mínimos da função para as nossas variáveis m e b.
Agora sabendo disso e da nossa abordagem nós vamos:
- Derivar a nossa Função de Custo para m e para b;
- Dando grandes passos quando estivermos muito longe do ponto mínimo;
- E passos curtos quando estivermos muito próximos do ponto mínimo.
Ou seja, como nós temos mais de uma variável, nós vamos aplicar o conceito de Derivadas Parciais, onde, nós Derivamos para uma variável e deixamos a outra como constante e depois fazemos o mesmo para a outra e vamos diminuindo até achar os pontos mínimos possíveis para os coeficientes m e b:
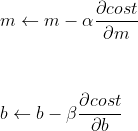
Ahh, entendido, mas tem 2 observações na abstração acima:
- 1ª — Nós temos 2 constantes α (Alpha) e β (Beta) que estão multiplicando as nossas Derivadas Parciais;
- 2ª — Nós estamos Derivando a nossa Função de Custo para as variáveis m e b da equação da reta .
06 — A Regra da Cadeia
Por enquanto (mas só por enquanto) vamos ignorar as constantes α (Alpha) e β (Beta) e vamos relembrar um conceito matemático chamado: Regra da Cadeia.
Em cálculo, a Regra da Cadeia é uma fórmula para a derivada da função composta de duas funções, What?
Ok, vamos para os exemplos, suponha que nós temos as seguintes funções:
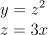
Veja que agora nós temos 2 funções y e z, onde:
- O meu y depende de z;
- E o meu z depende de x.
Agora eu quero Derivar a minha função y para x:
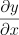
Ué, como vai ser? Se o meu y depende do z; e o meu z depende do x?
A REGRA DA CADEIA:
É ai que entra o conceito da Regra da Cadeia. Basta seguir a fórmula abaixo:
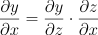
Agora é só tirar a Derivada de y para z; e de z para x; e depois multiplicar elas… Vai ficar assim:
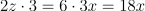
NOTE:
É importante lembrar que algumas dessas variáveis tem relações com outra, por exemplo, o meu z = 3x, por isso nós mudamos isso na hora de trabalhar a equação.
Mas no fim o que importa é que a Derivada da função y em relação a x é 18x.
07 — Aplicando a Regra da Cadeia na Função de Custo
Ok, agora que nós já revisamos o conceito da Regra da Cadeia, como eu posso aplicar ela na minha Função de Custo para os coeficientes m e b?
Bem, vamos ver as relações né? Primeiro vamos pegar nossa Função de Custo:
Ok, dentro da Função de Custo nós temos a função regi que depende de m; E a minha Função de Custo que depende de regi. Ué, só aplicar a Regra da Cadeia então…
NOTE:
Primeiro vamos apelidar nossa função (regi + yi)^2 de error para ficar uma abstração mais nominal.
Agora é só tirar a Derivada da Função de Custo para m seguindo a Regra da Cadeia:
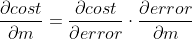
- Veja que a minha Função de Custo depende do error; e o meu error depende de m;
- Agora é só tirar a Derivada da minha Função de Custo para o error; e do meu error para m e depois multiplicar:
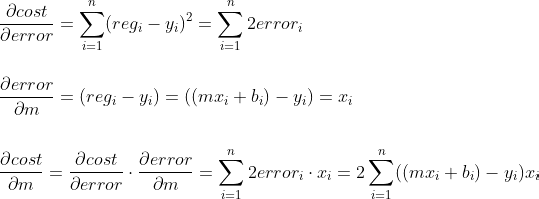
Simplificando, a Derivada da minha Função de Custo para m vai ser :
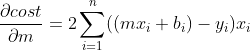
Ótimo, agora é só tirar a Derivada da Função de Custo em relação a b:
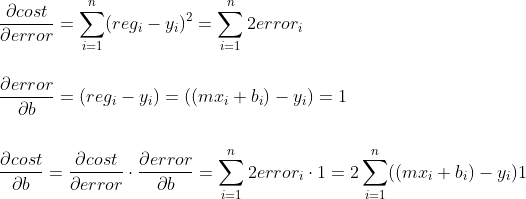
Simplificando novamente:
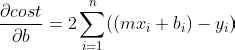
Pronto, resolvido!
Agora nós já temos as Derivadas da Função de Custo para m e b:
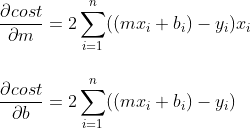
Como os nossos xi e yi são valores que nós já temos no gráfico (nossos dados) nós só vamos Derivando os coeficientes m e b até chegar o mais próximo possível do mínimo da Função de Custo, seguindo a nossa abordagem:
Caminhando rápido quando a gente está muito longe; E caminhando devagar quando a gente está muito perto.
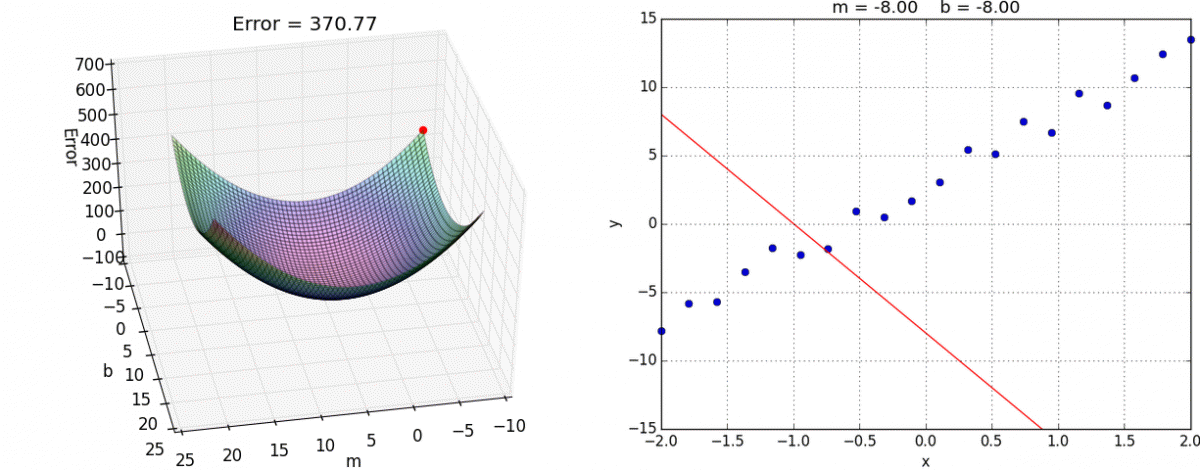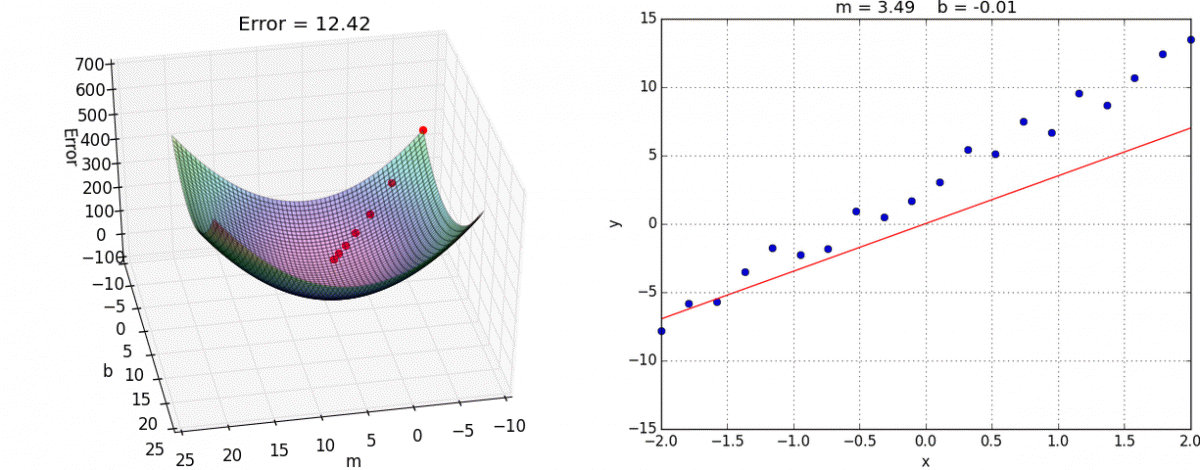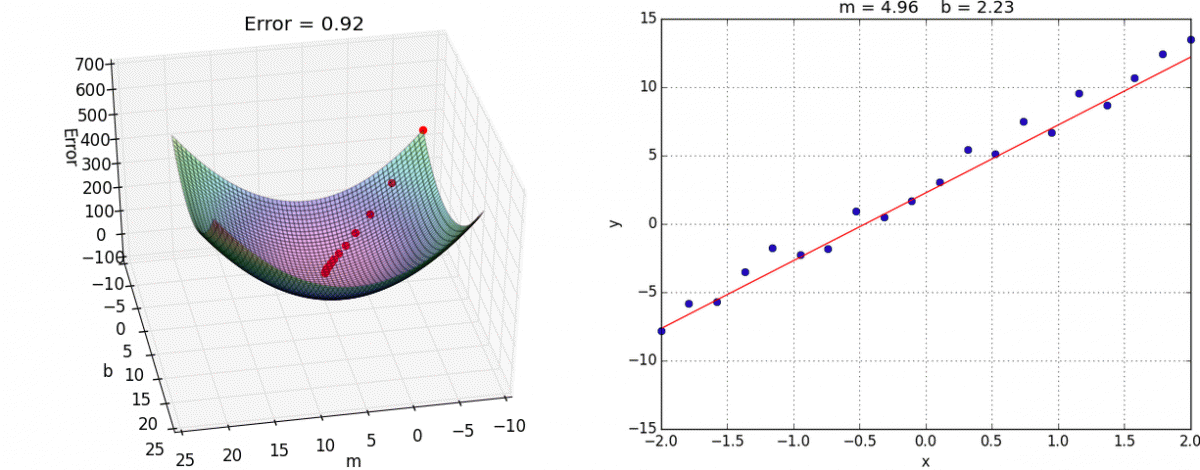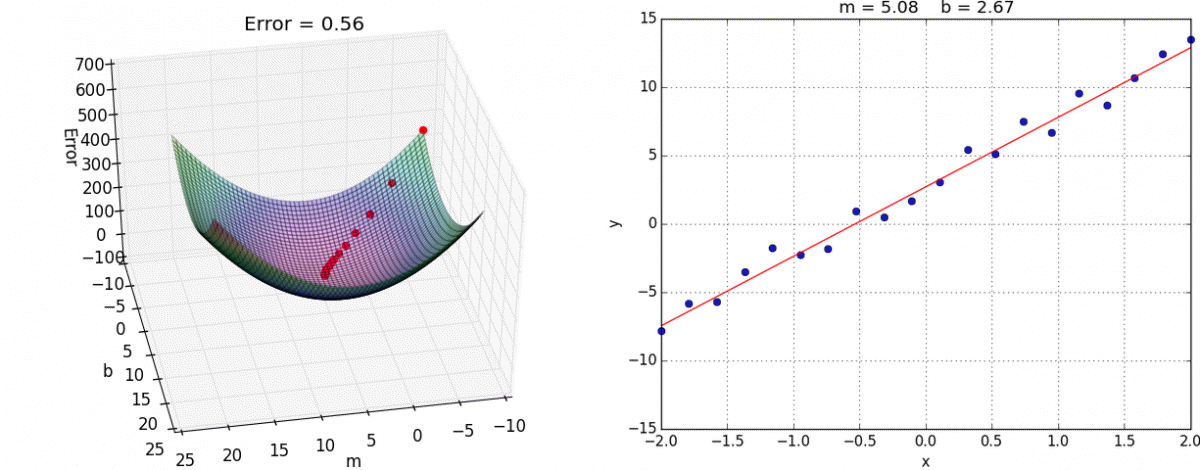
08 — Taxa de Aprendizagem (Learning Rate)
Ok pessoas… Voltando alguns passos atrás, lembram que nós tinhamos umas constantes que multiplicavam nossas Derivadas da Função de Custo para m e b? Eram as constantes α (Alpha) e β (Beta), mas o que elas significavam?
Então, isso é o que nós chamamos de Taxa de Aprendizado (Learning Rate), responsáveis por ajuste e determina o tamanho da etapa em cada iteração enquanto se move em direção ao Mínimo de Função de Custo.
A Taxa de Aprendizado (Learning Rate) é um hiperparâmetro que controla o quanto alterar o modelo em resposta ao erro estimado cada vez que os pesos do modelo são atualizados. Escolher a taxa de aprendizado é desafiador, pois um valor muito pequeno pode resultar em um longo processo de treinamento que pode travar, enquanto um valor muito grande pode resultar no aprendizado de um conjunto sub-ótimo de pesos muito rápido ou um processo de treinamento instável.
Seguindo a nossa abordagem de Gradiente Descendente a Taxa de Aprendizado (Learning Rate) vai determina o tamanho dos nossos passos em direção ao Mínimo da Função de Custo.
Veja os exemplos abaixo:
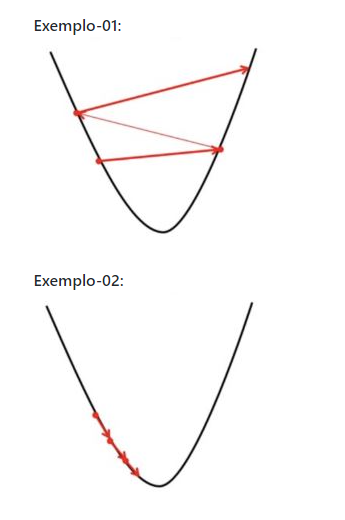
09 — Aplicando o Método do Gradiente Descendente na prática
Ok, mas depois de todas essas bruxarias teóricas, como colocar tudo isso em prática? Bem, vamos ver isso agora com Python sem precisar importar nenhuma biblioteca (mas só por agora):
OUTPUT:
Angular Coefficient (m): 1425
Linear Coefficient (b): -7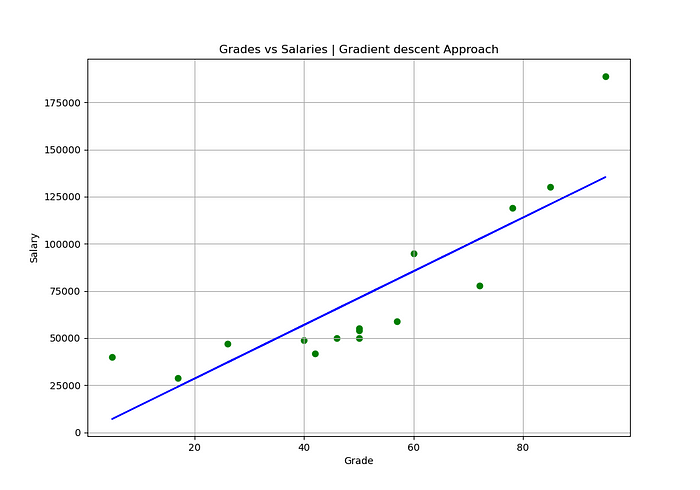
NOTE:
Veja que com o Método do Gradiente Descendente nós conseguimos melhores valores para os coeficientes m e b em relação ao Método dos Mínimos Quadrados Ordinários (OLS).
10 — Criando uma Reta de melhor ajuste com com Scikit-Learn
Ok, até aqui já vimos todas essas bruxarias matemáticas e teóricas, mas como resolver isso na prática (E de maneira simples é claro!)?
Graças ao Python e a maravilhosa comunidade Open-Source nós temos a biblioteca Scikit-Learn que deixa todo esse trabalho MUITO FÁCIL! Vamos começar instalando a biblioteca:
pip install scikit-learn --upgradeNOTE:
Se você estiver utilizando um ambiente virtual (assim como eu) é recomendado salvar essa dependência:
pip freeze > requirements.txtOk, agora vamos ver a nossa versão atual do Scikit-Learn?
OUTPUT:
Scikit-Learn Version: 0.23.1Ótimo, tudo lindo e maravilhoso a nossa disposição! Mas como eu crio um exemplo de Regressão Linear?
Simples, primeiro vamos criar um conjunto de dados aleatórios (mesmo sem sentido) para representar o nosso conjunto de dados:
OUTPUT:
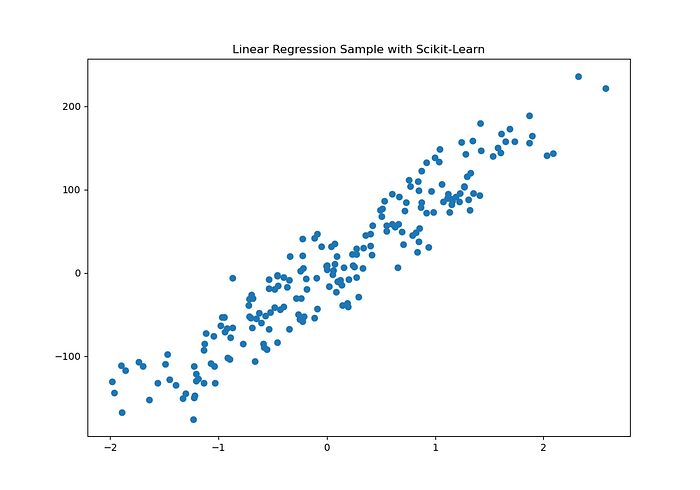
A biblioteca Scikit-Learn tem um método chamado make_regression que pode ser usado para criar um conjunto de dados para que possamos trabalhar com eles. Os argumentos mais comuns (que foram o que nós utilizamos) para esse método são:
- n_samples: O número de Amostra de Dados;
- n_features: O número de variáveis/características;
- noise: Quanto ruído terá nosso gráfico, ou seja, quão bagunçado vai está os dados.
NOTE:
Poré, toda vez que você rodar esse código vai ser gerado um conjunto de dados diferentes. Ou seja, vai ser outro gráfico/plot.
NOTE:
Outra observação importante que você deve prestar atenção é que a função make_regression nos retornou 2 conjuntos de dados — x e y, ou seja:
x, y = make_regression(n_samples=samples, n_features=variavel_numbers, noise=n_noise)- Os valores aleatórios criados para o nosso eixo-x;
- E os seus correspondente no eixo-y.
Ótimo, agora voltando para o nosso problema (Regressão Linear):
Como crio uma reta de melhor ajuste com Scikit-Learn?
Dá para fazer isso de forma automática e simples? Claro, com Scikit-Learn e suas bruxarias:
OUTPUT:
Angular Coefficient (m): [34.34928509]
Linear Coefficient (b): -0.23447017542042375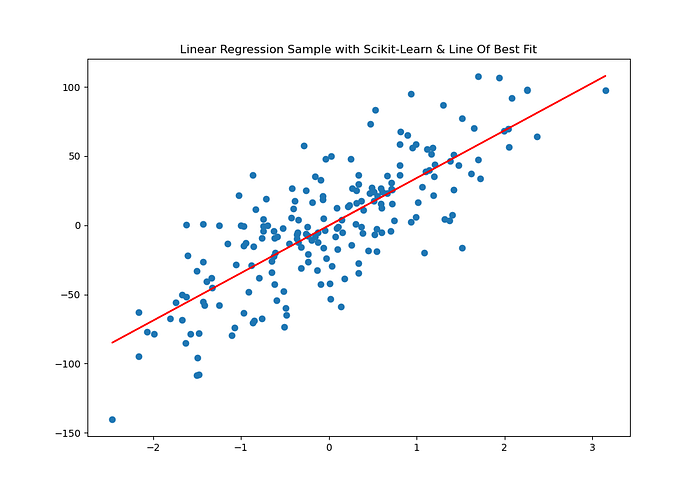
11 — Dividindo os dados em Treino e Teste
Uma coisa que vocês tem que entender primeiro é que os modelos de Machine Learning aprendem a partir de dados. Sabendo disso é interessante dividir nosso conjunto de dados em Dados de Treino & Dados de Teste.
DADOS DE TREINO:
Ok, suponha que nós queremos desenvolver um programa (modelo) que identifique se uma imagem é um cachorro ou não é um cachorro.
De início nós vamos receber um conjunto (amostra) com várias imagens de cachorros, depois nós vamos pegar uma parte desse conjunto (normalmente 70%) e dar para o nosso modelo aprender identificando características comuns entre cachorros.
DADOS DE TESTE:
Ok, Nós reservamos 70% do nosso conjunto de dados (amostra) para o nosso algoritmo aprender e os outros 30%?
Então, esses são os Dados de Testes. Nós vamos passar os dados de testes para o nosso modelo e ver quão bem ele está aprendendo. Por exemplo:
Isso aqui é um cachorro?

E o nosso modelo vai ter que dar um retorno dizendo se é um cachorro ou não.
NOTE:
Viram como é interessante dividir o conjunto de dados (amostra) em treino e teste? Outro exemplo, seria identificar uma doença em pacientes, como nós saberíamos se nosso modelo aprendeu (ou está aprendendo) bem se deixar ele aprender com todo o conjunto de dados?
Por isso, ele vai aprender com uma parte (70% no nosso caso) e vamos reserva outra parte (30% no nosso caso) para testar e ver quão bem ele (nosso modelo) está aprendendo.
OUTPUT:
Angular Coefficient (m): [4.65851642]
Linear Coefficient (b): 0.760506738734484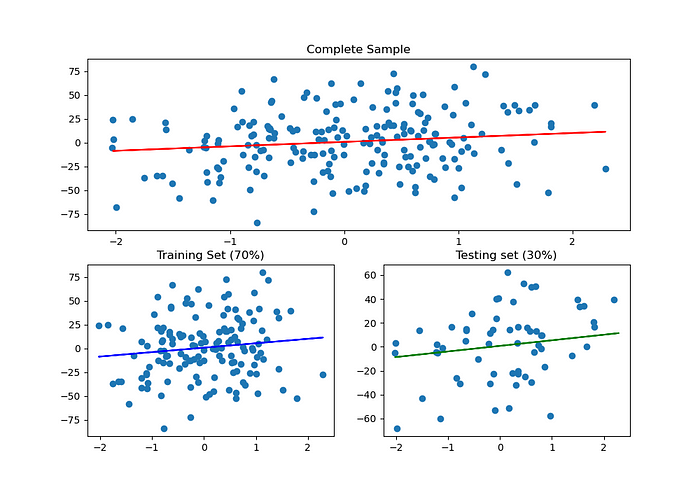
12 — Pegando o Coeficiente de Determinação R2 com Scikit-Learn
Bem, antes de pegar o Coeficiente de Determinação R^2 com Scikit-Learn, você sabe que bixo é esse? Não? Ok, vamos para uma breve explicação…
Suponha que nós criamos um gráfico com alguns dados para ver a relação entre preços de casas e seus tamanhos, ficou algo parecido com isso (e não muito bonito):

Se você prestar atenção vai ver que o nosso gráfico tem uma variação crescente, ou seja:
A medida que aumenta o preço o tamanho também aumenta — vice e versa.
Agora suponha que eu quero criar um modelo que use uma reta para representar esses dados, de maneira que se eu inserir um novo preço ele tente descobrir (prever) qual o tamanho da casa.
NOTE:
A primeira ideia que nós vamos ter é calcular a média dos tamanhos e traçar uma reta. Suponha que a reta ficou assim:
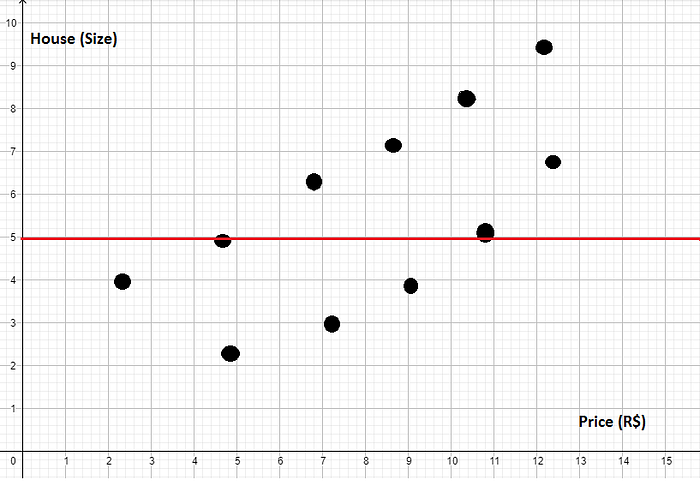
Bem, essa reta não representa muito bem esse modelo. Se você prestar atenção vai ver que temos bastante erro. Como nós poderíamos calcular o erro desse módelo?
- 1º — É só pegar cada um dos valores (pontos no gráfico);
- 2º — Calcular a distância para a minha reta:
No gráfico as distâncias dos pontos para a reta você pode ver assim:
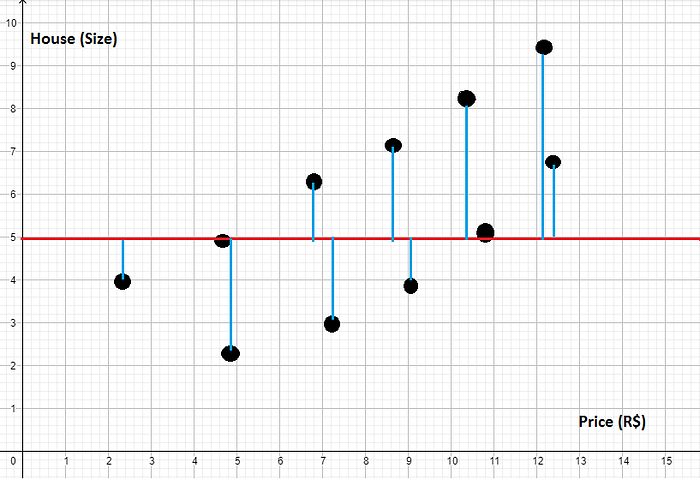
Isso é o que nós conhecemos como Soma dos Quadrados Totais — SQt
NOTE:
Na verdade o que nós fizemos acima foi tirar a variância dos nossos dados.
Continuando… Agora suponha que eu criei um novo modelo, porém com uma reta que parece se alinhar melhor com esses dados, veja abaixo:
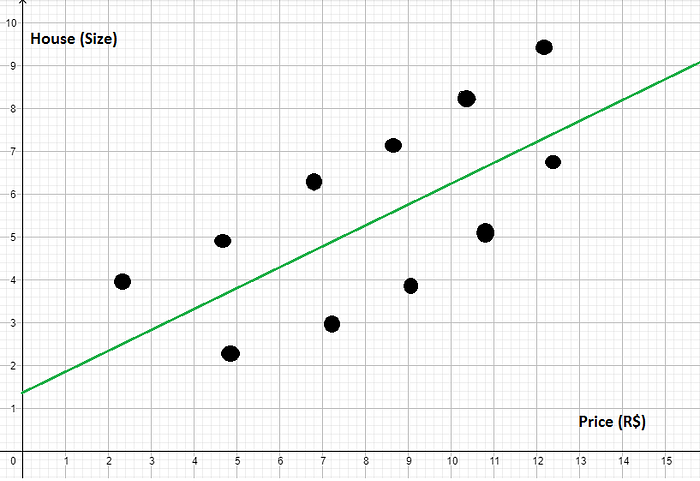
Ok, só de olhar já da para ver que essa reta representa bem melhor esses dados do que apenas tirar a média dos erros de todos os dados.
A final ela parece está crescendo a mesma taxa que esses dados estão crescendo.
Mas, como eu posso provar que realmente essa segunda reta está melhor do que a outra? Ué, é só calcular cada uma dessas distâncias entre nossos dados e a reta verde (nova reta):
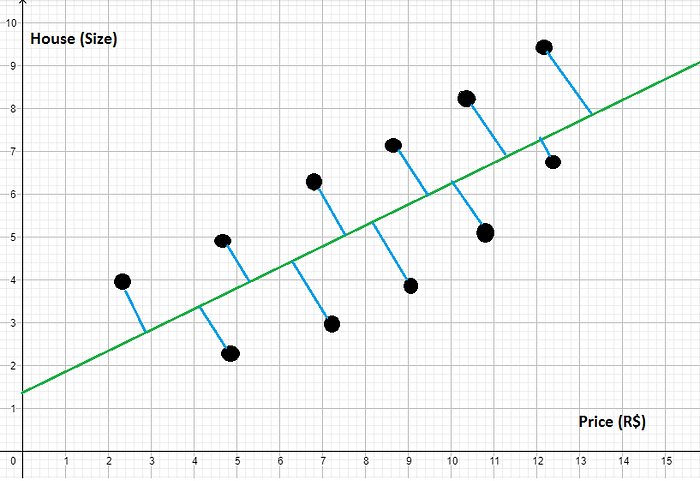
Isso é o que nós conhecemos como Soma dos Quadrados dos Resíduos — SQres
Ok, se nós calcularmos os dados nós vamos ver que o meu SQres é menor do que o SQt. Ou seja, o meu SQres está melhor ajustado.
NOTE:
Mas como eu sei quão melhor está o meu SQres em relação ao SQt? — Ou seja, quão melhor ele está em relação a média?
Coeficiente de determinação R2:
Então, é ai que entra o nosso querido R2… O R2 nada mais é do que o meu SQt menos SQres dividido pelo SQt:
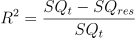
Mas o que essa fórmula realmente significa na prática?
- Númerador: Bem, no numerador nós vemos quão bem o meu modelo SQres é em relação ao SQt;
- Denominador: Quando nós dividimos pelo SQt nós estamos normalizando, ou seja, nós estamos trazendo esse valor para uma escala que vale entre zero e um.
Mas por que normalizar entre zero e um?
Ok, vamos ver… Suponha que nós criamos um modelo de Machine Learning muito ruim que criou uma reta que foi igual a soma dos quadrados totais SQt, mais ou menos isso:
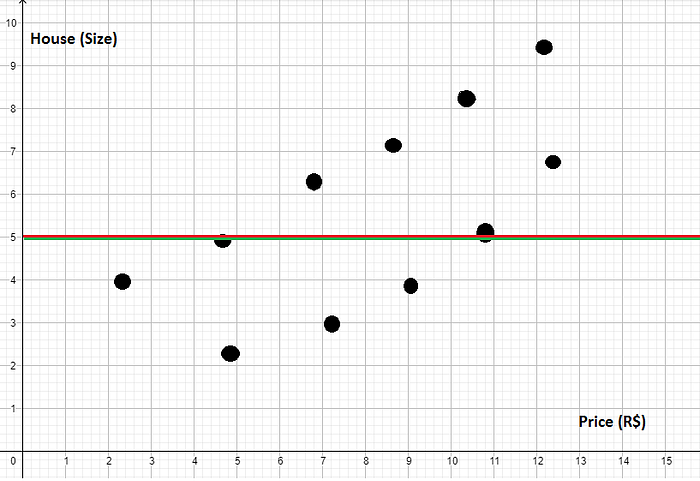
Ué, o meu SQres vai ser igual ao meu SQt, logo, o meu R2 vai ser zero:
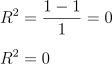
NOTE:
Agora vamos imaginar outro cenário (é só exemplo) onde os meus dados estão distribuídos de uma forma onde meu modelo de Machine Learning passe exatamente por todos os dados, ou seja, não teve nenhum erro:
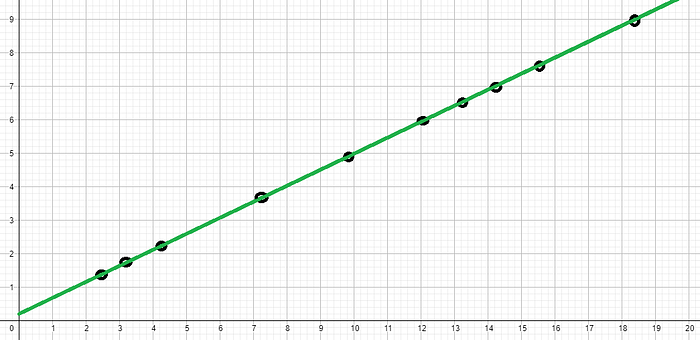
Então, como o nosso SQres não teve nenhum erro, qual vai ser nosso R2 agora?
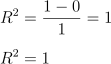
Ótimo, mas o que o nosso R2 nos diz?
- Quanto maior (mais perto de 1) o R2 melhor vai ser o meu cenário;
- Quanto menor (mais perto de 0) o R2 pior vai ser o meu ceunário.
Mas como nós poderíamos interpretar o nosso R2? Por exemplo:
Eu criei um modelo de Machine Learning que gerou o R2 de 0,87.
O que isso significa?
Significa que o meu modelo de Machine Learning é 87% melhor do que simplesmente pegar a média dos valores.
Outra abordagem de interpretação é dizer que o meu modelo explica 87% da variância dos dados. Como assim?
Lembre que o cálculo do SQt é o cálculo da variância do nosso conjunto de dados. Ou seja, o resultado total da variância.
Enquanto o meu SQres mostra quanto desta variância foi explicada. Se o meu R2 fosse 1 significaria que 100% da variância teria sido explicada — zero erro na reta.
Ta, mas como eu programo essa bruxaria toda ai? Simples, veja o código abaixo:
OUTPUT:
Coefficient of Determination: R^2: 0.9158177316382643Ótimo, pegamos o nosso R2 que foi 0.91 ou seja, nós explicamos 91% do nosso conjunto de dados. Agora vamos ver qual foi a parte do código que fez isso e qual foi a lógica:
Primeiro nós criamos um modelo com os dados de treino:
model.fit(x_train, y_train)E depois apenas com os dados de teste nós pegamos o R2 com o método score():
# Coefficient of Determination: R^2 / R-Squared.
r2 = model.score(x_test, y_test)13 — Usando o conceito de Regressão Linear & R2 em um conjunto de dados reais + random_state
Ótimo, já aprendemos como dividir os dados em treino e teste, como funciona o Coeficiente de Determinação R2, mas como trabalhar em um conjunto de dados reais tudo isso?
Agora vamos trabalhar com o Dataset do município King County localizado no estado de Washington nos Estados Unidos da América (USA). Esse Dataset pode ser baixado facilmente dando uma Googlada ou você pode vir aqui no Kaggle.
Basicamente esse Dataset tem dados das casas vendidas no município de King County. Esses dados são formados por 21 colunas, que são:
- id — ID da casa;
- date — Data em que a casa foi vendida;
- price —
Preço é meta da previsão; - bedrooms — Número de quartos casa;
- bathrooms — Número de banheiros da casa;
- sqft_living — Metragem quadrada da casa
- sqft_lot — Metragem quadrada do lote;
- floors — Pisos totais (níveis) em casa;
- waterfront — Casa com vista para a água (mar/lagoa);
- view — Foi visualizado;
- condition — Quão boa é a condição (geral);
- grade — Nota geral dada à unidade habitacional, com base no sistema de classificação de King County;
- sqft_above — Metragem quadrada de casa além do porão;
- sqft_basement — Metragem quadrada do porão;
- yr_built — Ano de construção;
- yr_renovated — Ano em que a casa foi reformada;
- zipcode — Código postal (CEP no Brasil);
- lat — Coordenada de latitude;
- long — Coordenada de longitude;
- sqft_living15 — Área da sala de estar em 2015 (implica — algumas reformas) Isso pode ou não ter afetado a área de tamanho grande;
- sqft_lot15 — Área lotSize em 2015 (implica — algumas reformas).
NOTE:
Até então nós estavamos trabalhando apenas com duas variáveis, onde tinhamos o meu ponto x e o seu correspondente y e ficava muito fácil criar uma Regressão Linear em um plano bidimensional.
Só lembrando a fórmula de Regressão Linear era essa:
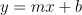
Agora nós temos que aplicar essa fórmula no nosso Dataset King County, porém, ele tem várias variáveis Como isso se aplica na prática?
RESPOSTA:
Então, a lógica vai ser a mesma… Porém, ao invés de y = mx + b nós vamos ter:
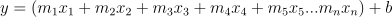
Ótimo, entendido! Mas como aplicar isso em Python e Scikit-Learn e pegar o nosso Coeficiente de Determinação R2?
OUTPUT:
Coefficient of Determination: R^2: 0.6608668622831475Ou seja,
- Significa que o meu modelo de Machine Learning é 66% melhor do que simplesmente pegar a média dos valores;
- Ou, o meu modelo explica 65% da variância dos dados.
NOTE:
Outra observação é que talvez o seu resultado seja diferente. Isso porque o método train_test_split() separa os dados de treino e testes aleatoriamente.
Isso pode ser ruim em alguns casos, por exemplo, nós estamos ajustando os pesos das variáveis para encontrar um R2 melhor para o nosso modelo. Como resolver isso?
random_state:
O método train_test_split() também pode receber um argumento chamado random_state. Como ele basicamente nós passamos um inteiro e é feito um embaralhamento dos dados, onde, sempre que você ou qualquer pessoa executar o método train_test_split() no mesmo conjunto de dados, os dados de treino e testes serão os mesmo se ambos tiverem o mesmo argumento random_state.
Veja abaixo como fica:
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=10)OUTPUT:
Coeficiente de Determinação R^2: 0.6608668622831475NOTE:
Agora se você ou qualquer outra pessoa executar a mesma amostra de dados com o random_state=10 os dados de treino e testes vão ser sempre o mesmo.
Ou seja, o Coeficiente de Determinação R2 vai ser sempre o mesmo.
14 — Fazendo previsões
Ótimo, até então nós fizemos vários exemplos de Regressão Linear; E pegamos o Coeficiente de Determinação R2.
Mas como tentar ver previsões com os nossos modelos?
Vamos começar com uma nova abordagem… Suponha que nós amamos pizzas e nos últimos dias nós compramos 15. Sabendo que nós compramos muitas pizzas vamos tentar prever qual o preço de uma pizza de acordo com o seu diâmetro.
Então, os dados das nossas 15 pizzas foram os seguintes:
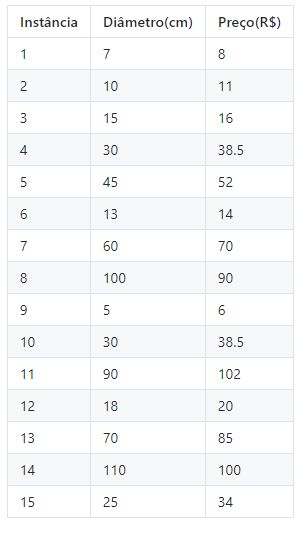
Ótimo, primeiro vamos fazer todo aquele paranauê:
- Dividir os dados em treino e teste;
- Criar uma reta de Regressão Linear que melhor explique essa relação;
- Pegar o Coeficiente de Determinação R2;
- E por fim, criar um gráfico com tudo isso.
Vai ficar assim:
OUTPUT:
Coeficiente de Determinação R^2: 0.9231014405990501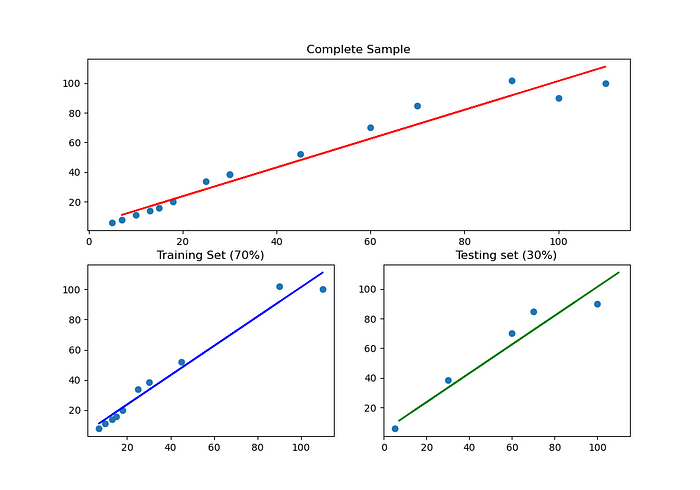
Ok, isso nós já aplicamos várias vezes, mas agora eu quero saber o seguinte:
Se eu desejar comprar uma pizza de 20cm diâmetro qual vai ser o preço?
A classe LinearRegression além do método fit() utilizado para treinar nosso modelo, também tem o método predict() que utiliza o nosso modelo linear para tentar fazer previsões.
Veja como fica isso com o código abaixo:
OUTPUT:
What's the diameter(cm) of the pizza you want? 20
A 20.0 cm diameter pizza should cost:: R$24.0NOTE:
Na verdade nós fizemos ainda melhor do que tentar prever só para uma pizza de 20cm de diâmetro. Nós criamos um programa de Machine Learning que para qualquer diâmetro passado, ele vai retorna qual será mais ou menos o preço da pizza para esse conjunto (amostra) de dados.

REFERENCES:
Didatica Tech — MÓDULO — I
A matemática do Gradiente Descendente & Regressão Linear (machine learning)
Metodo da Descida do Gradiente
AULA 5 — GRADIENTE DESCENDENTE EXPLICADO — CURSO DE INTELIGÊNCIA ARTIFICIAL PARA TODOS
Optimization: Ordinary Least Squares Vs. Gradient Descent — from scratch
Rodrigo Leite, Software Engineer.
